Blog
-

Building a WooCommerce CSV Cleaner Using Python and AI (Part 1)
Today felt like a shift from just learning concepts to actually building something practical. Instead of focusing on small exercises, I worked on a real problem I’ve encountered many times in my experience as a WordPress and Laravel developer—messy WooCommerce product CSV files. If you’ve ever imported products into WooCommerce, you probably know the pain:
-
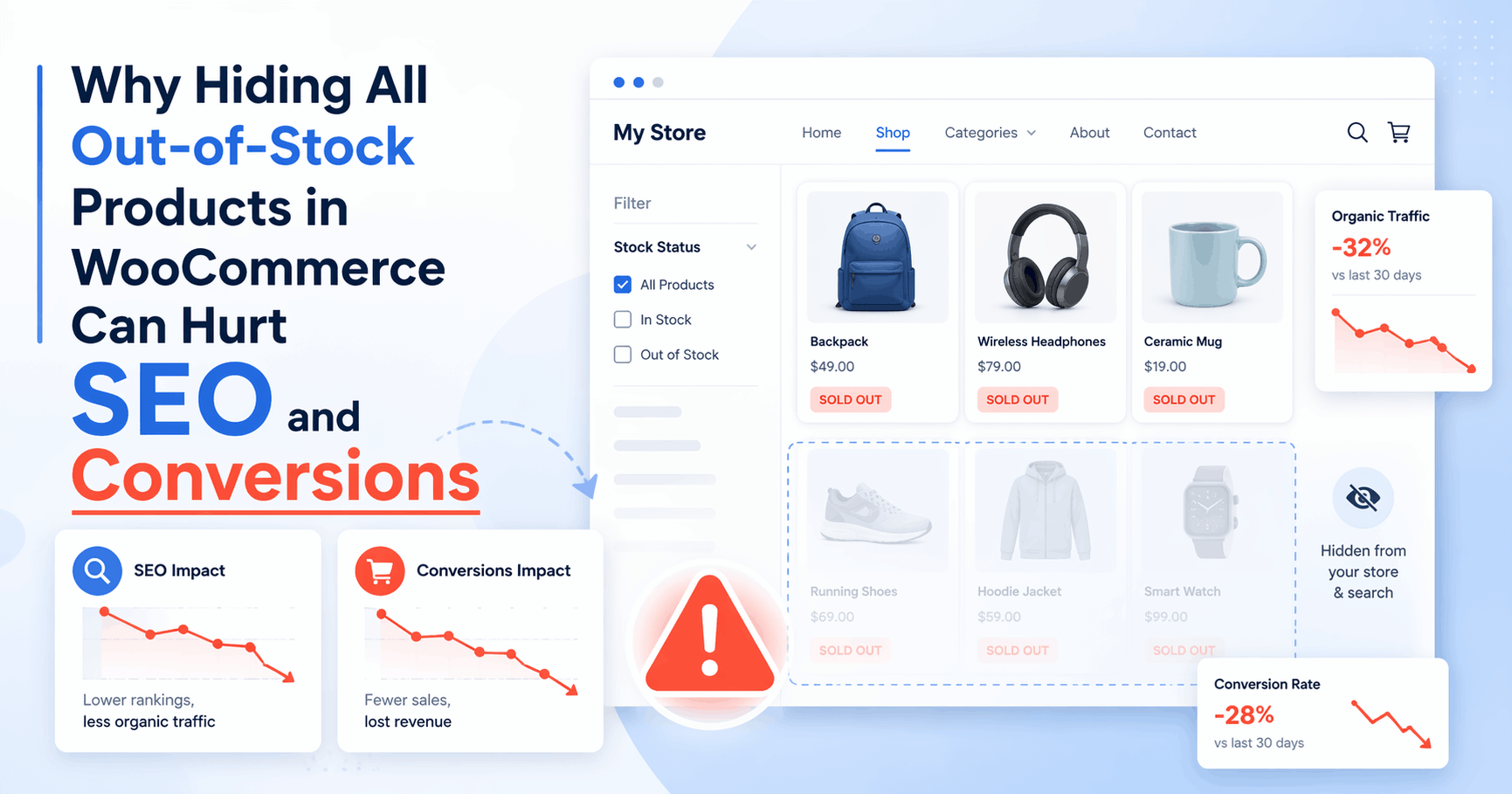
Why Hiding All Out-of-Stock Products in WooCommerce Can Hurt SEO and Conversions
If you run a WooCommerce store, it might seem like a good idea to hide all out-of-stock products from your catalog. At first, it feels clean and logical. If a product cannot be purchased right now, why keep showing it? But in many cases, hiding every out-of-stock product can do more harm than good. It
-
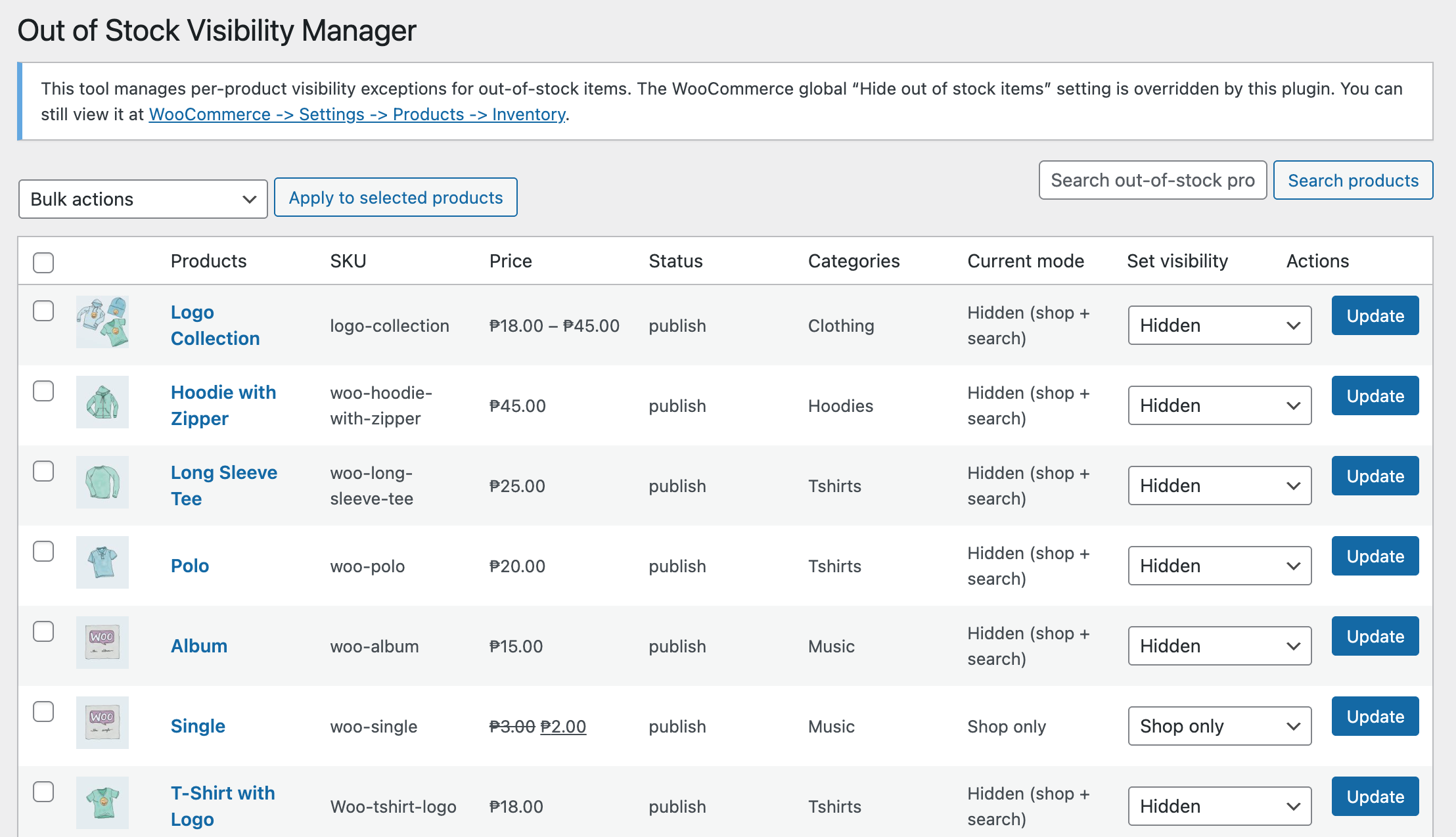
How to Hide or Show Out-of-Stock Products in WooCommerce (Per-Product Control)
Many WooCommerce store owners want to hide out-of-stock products in WooCommerce while still being able to show specific out-of-stock items when needed. Unfortunately, WooCommerce only provides a global hide out-of-stock setting. Once enabled, all out-of-stock products disappear from the shop and search results — with no way to control visibility per product. If you’ve ever
-
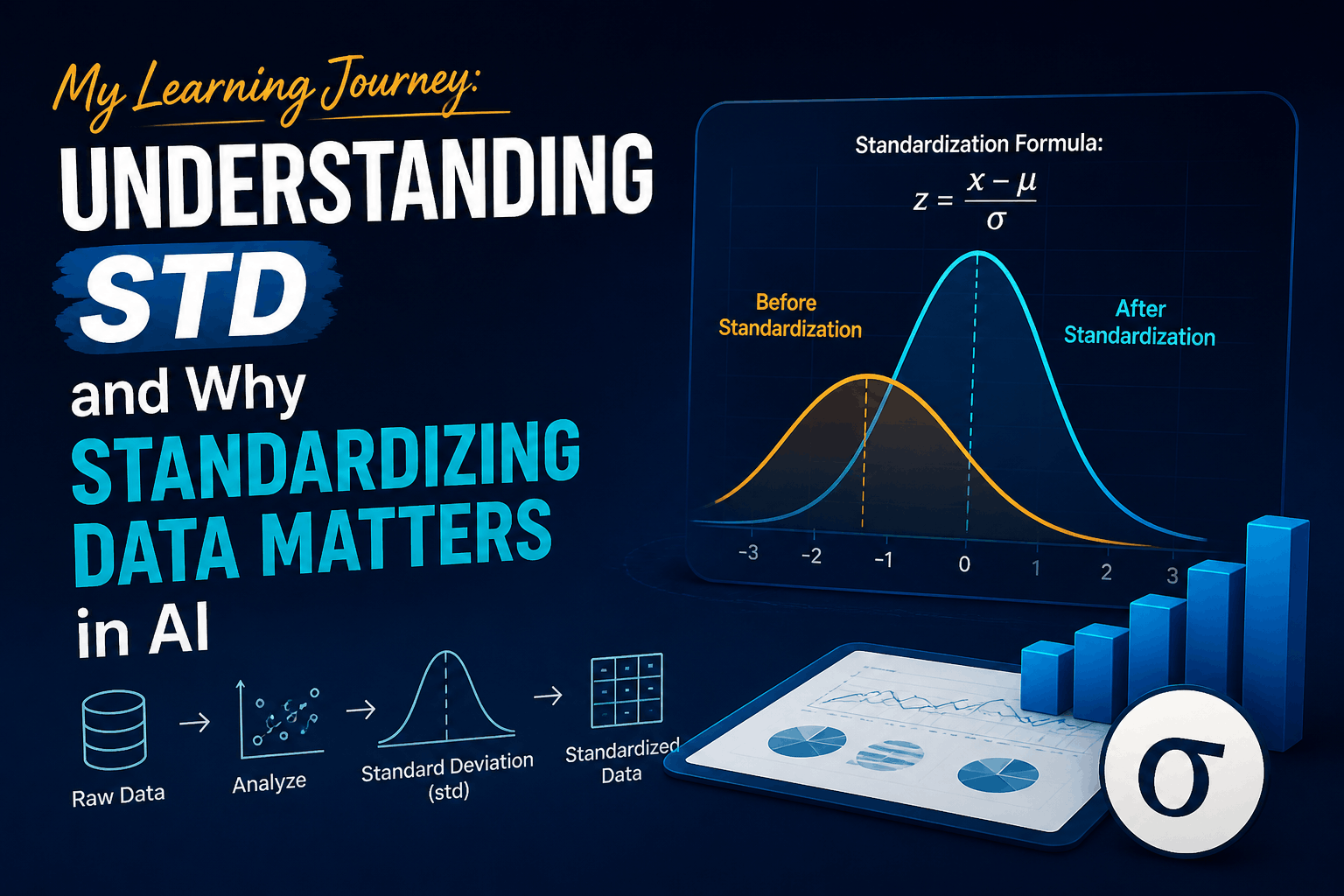
My Learning Journey: Understanding std and Why Standardizing Data Matters in AI
Today, I dove into something that’s surprisingly important in the world of data science and machine learning — the standard deviation, often written as std, and its crucial role in standardizing data. As someone transitioning into AI and data work from a strong background in full-stack development (especially PHP, Laravel, and WordPress), I always believed
-
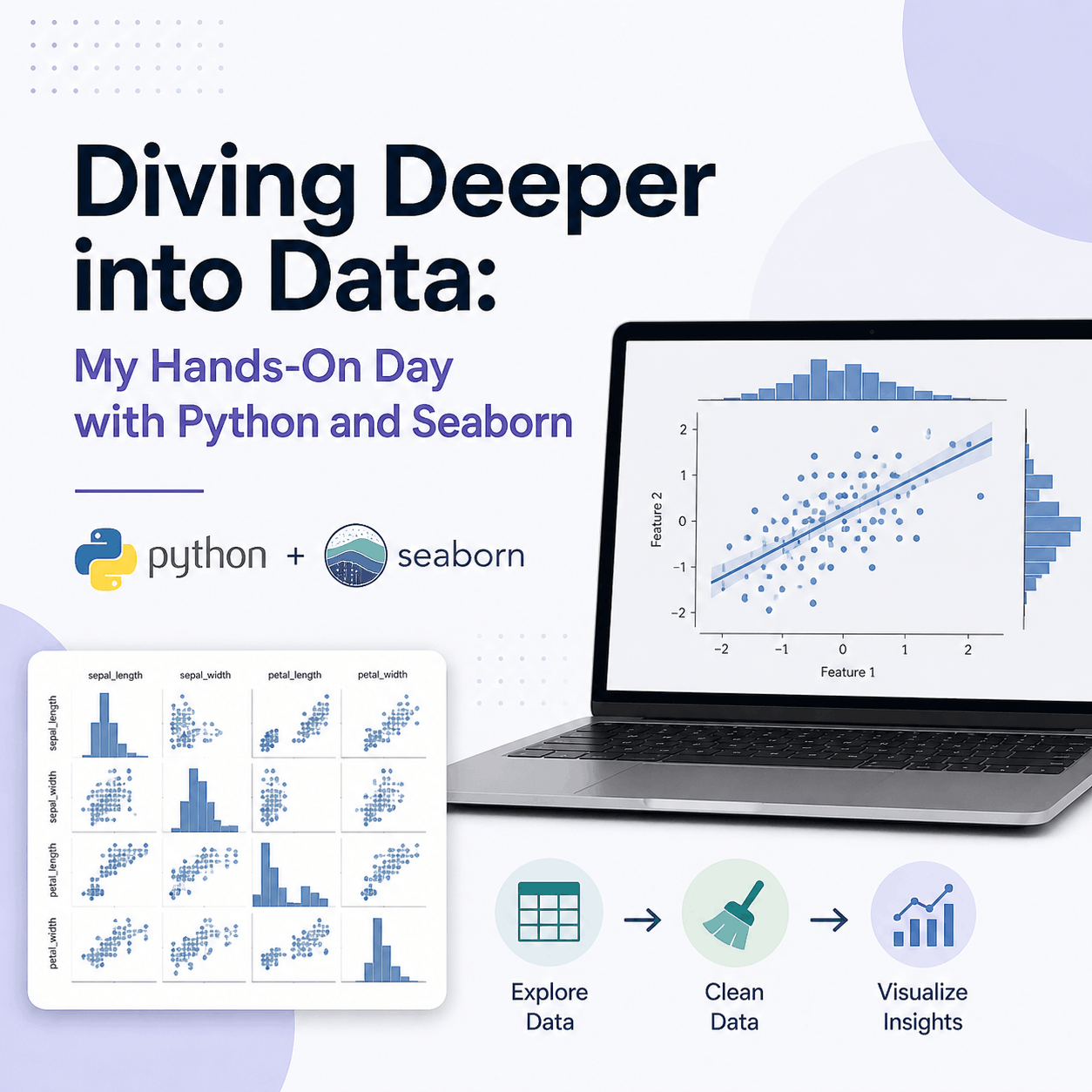
Diving Deeper into Data: My Hands-On Day with Python and Seaborn
Today was one of those days where everything just clicked a little more. I’m still new to the world of AI and data science, but every session brings a new layer of understanding—and today was all about digging into datasets and making sense of them visually. I started off with something pretty simple but powerful:
-
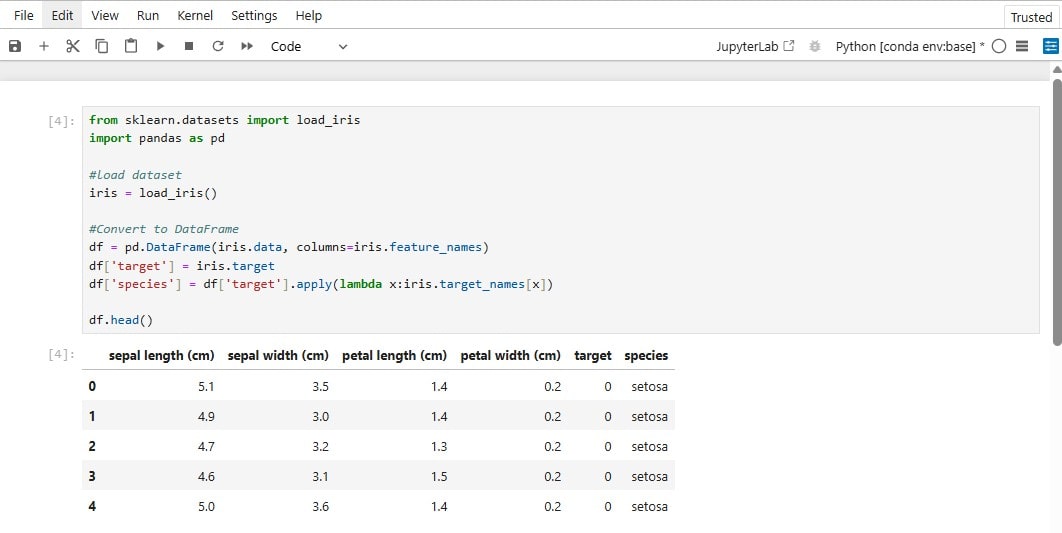
My First Step Into the World of AI: Learning Python for Data Science
For over a decade, I’ve been immersed in the world of web development, building solutions and applications using PHP through frameworks like Laravel and platforms like WordPress. My day-to-day experience has been rooted in backend logic, plugin development, and creating practical web tools that solve real problems. But recently, I took a leap into something