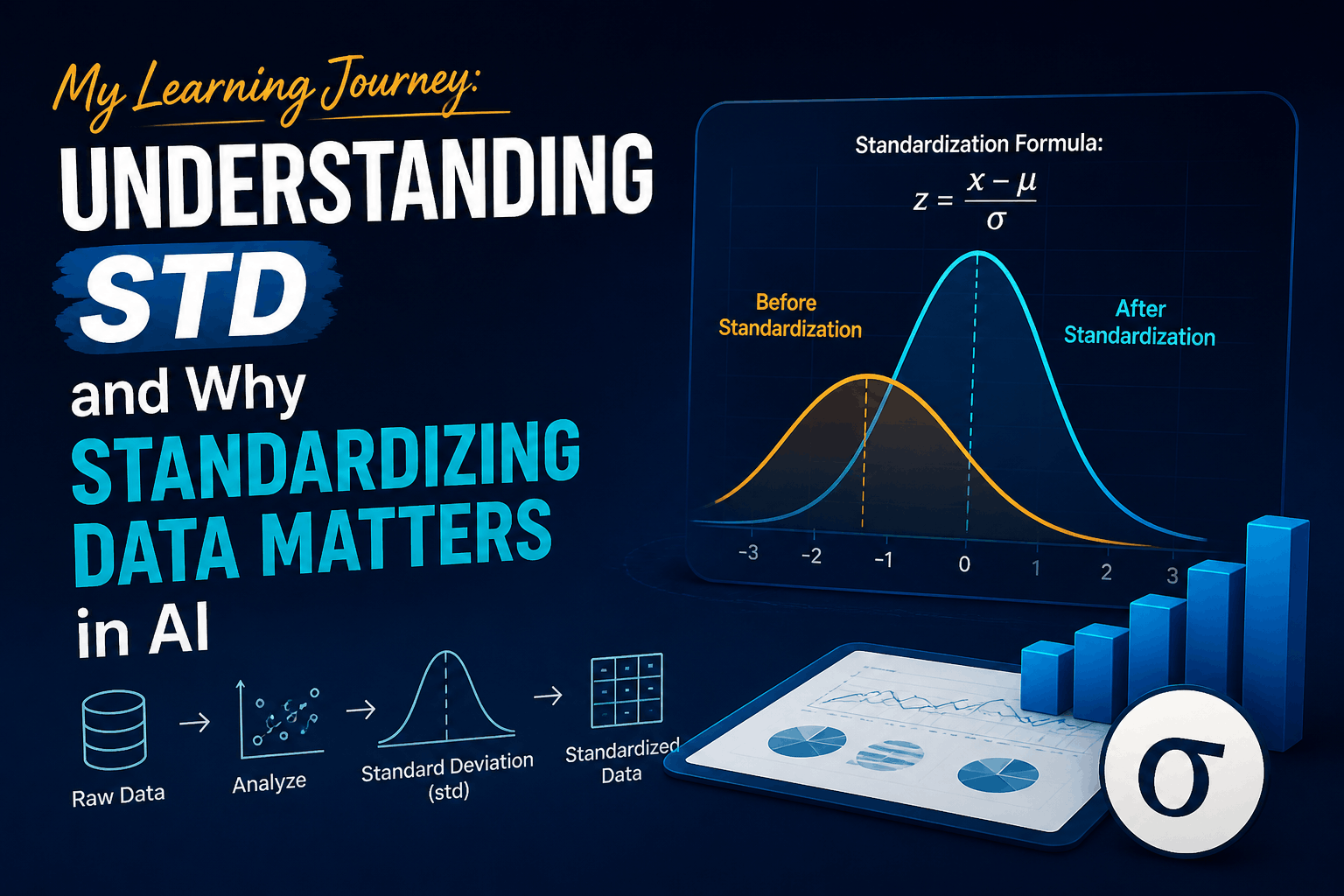
Today, I dove into something that’s surprisingly important in the world of data science and machine learning — the standard deviation, often written as std, and its crucial role in standardizing data.
As someone transitioning into AI and data work from a strong background in full-stack development (especially PHP, Laravel, and WordPress), I always believed numbers were just… numbers. But this journey taught me otherwise.
What is std?
In basic terms, std (standard deviation) measures how spread out the values in a dataset are. A low standard deviation means the values are close to the mean (average), while a high standard deviation means the values are more spread out.
Let’s take an example:
import numpy as np
ages = [25, 30, 35, 40, 45]
mean_age = np.mean(ages) # 35
std_age = np.std(ages) # ~7.9
Here, the standard deviation of the ages is around 7.9. This tells us that, on average, each age is about 7.9 years away from the mean (35).
Why Should We Standardize Data?
Now, here’s where it gets interesting. In machine learning, we often deal with multiple features (like age, salary, height, etc.). Each of these might be on completely different scales. For example:
- Age: 25 to 70
- Salary: 30,000 to 200,000
Without standardization, the model might treat “Salary” as more important just because it has bigger numbers — even if it’s not more predictive.
Standardization Formula:
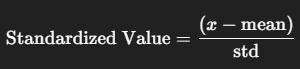
This process rescales your data so that each feature has a mean of 0 and a standard deviation of 1. Here’s a simple example in Python:
ages = [25, 30, 35, 40, 45]
mean = np.mean(ages)
std = np.std(ages)
standardized_ages = [(x - mean) / std for x in ages]
print(standardized_ages)
What Did I Learn?
Equal Weighting of Features
After standardization, different features are brought to the same scale. This helps machine learning models treat them fairly.
Easier Model Training
Some models, especially those based on distance (like KNN or SVM), perform much better with standardized data.
No Need to Do It Manually
While I learned how to manually calculate std, in real-world scenarios, we’ll mostly use libraries like scikit-learn‘s StandardScaler for this:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = [[25], [30], [35], [40], [45]]
standardized = scaler.fit_transform(data)
print(standardized)
Final Thoughts
Understanding std and data standardization might seem like a small thing, but it opened my eyes to how data influences model behavior. It’s not just about feeding numbers to a model — it’s about making sure those numbers mean something.
This lesson taught me that in AI, even the basic statistics matter a lot. And now, when I see a model giving weird results, I’ll know to check whether my data has been standardized properly.
This is just one step, but it’s a solid one on my journey into the world of AI and data science.
Leave a Reply